Update: the mystery is finally solved
Setting
This yesterday, I mistyped the URL as I was visiting Google this morning; I accidentally typed http://www.google.cm. This redirected me to a page on the domain of http://www.agoga.com, which actually looked like a somewhat convincing, spartan page, very similar in style to what you would often see if your browser. Except that it also contained a search bar, and a few unobtrusive links to subject like ‘Travel’, ‘Cars’ etc., the kind of subjects you would see on a typical parked domain page.
I thought that was kind of interesting, a way of monetizing typos that looked to me at least like it would be somewhat effective way of squatting a typo. At the time, though, it didn’t seem noteworthy enough to me to give it further thought.
A little later, I was trying to get to Paypal, and again I accidentally typed http://www.paypal.cm. Once again I was at the same page. I was intrigued, and began experimenting by checking a variety of other domains with the .cm extension. Many big names in the industry had the .cm TLD pointed to the same page I had viewed earlier.
That also, is not that notable. A squatter could easily have registered a whole variety of company names in that TLD - it’s done all the time, and is considered a valid tactic for making some money off of parked domains.
What made it notable finally is when I started entering random domains, and sequences of characters in the .cm TLD. such as http://sdfjhksd.cm and http://www.oiyt.cm. These also are pointing to a landing page on agoga.com, albeit a different landing page from the ones used on major domain mispellings.
Agoga.com has every unregistered .cm TLD pointed to their landing pages!
While there are a bunch of legitimately registered .cm sites which resolve elsewhere, any other .cm domain, whether nonsense characters or misspellings of ‘real’ domain names resolves to the same IP address which is a cluster at agoga.com. The only way this could be accomplished is to change the default site settings of the master DNS serving the .cm TLD. Agoga must have either hacked the .cm registrar in Cameroon, or paid the registrar off for this. Either way, I suspect something illegal has occurred here; I doubt this type of redirecting is approved by IANA.
Opportunity
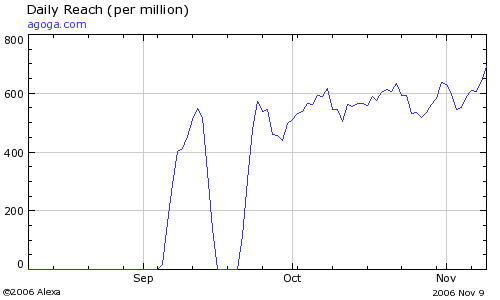
How much type-in traffic would you think would be generated by people misspelling .com as .cm? Agoga.com has an Alexa Rank of 6,915 which indicates thousands or tens of thousands of visitors per day by some estimates. Keep in mind that this site has not been running for even three months yet; today’s Alexa rank was 2,913.
Since Alexa ranking is biased towards a technical crowd, I think it is safe to assume that the true numbers are fairly large. Now, it is easily attainable that a proper landing page optimized for Pay-Per-Click advertisements will result in a 30%-40% click-through-rate. Especially if one was to put some effort into ensuring the advertisements were targeted around the domain name or keywords at the similar .com page.
It is obvious that with this type of traffic, Agoga.com could be pulling in some huge advertising revenue - as much a $1000-$2000 per day. They should have it made in the shade, for all intents and purposes. But, they have screwed up royally.
How did they screw up?
Agoga will return you to one of two landing pages, depending on what type of domain you enter. One version, which they seem to use when squatting the domain of a large company or popular website, can be seen at . The other, which they seem to use for the domains of smaller websites and nonsense or misspelled domains can be seen at http://www.oeiurt.cm (note the random domain name…) or http://www.caydel.cm (a typo of this domain) or at the Agoga main page at http://www.agoga.com.
The first type of landing page is broken - The first type of landing page is relatively well done - it is minimal, and could easily get the user to click onto their main site. The problem lies in that no ads are served if the user enters certain search queries. While an advertising page is shown if the user enters a query such as ‘digital cameras’, ‘dvd’, ‘knitting’, other queries such as ‘infohatter’, ‘caydel’ or whatever return nothing. Sure, probably nobody is bidding on that term; wouldn’t it be a better plan to grab the first result from a Google query for that term, scrape it for keywords, and return ads based on that? Potentially millions of long-tail opportunities are being missed here, thrown away for no good reason.
The second type of landing page broken - The script that Agoga used to generate the second style of landing page is broken. Any search query or link click redirects you to the same page you just left, with a nice photo of a mountain range, or other scenery visible in place of the advertisements that should be shown. They are making nothing from this type of landing page; in fact, they are losing money due to bandwidth costs.
Opportunity Missed
I would be willing to bet that the majority of the traffic that Agoga.com receives will end up at the second landing page, the broken one. While they probably have their highest traffic domains such as http://www.google.cm pointing to their ‘working’ script, they are missing out on the whole long-tail of domain misspellings. Think about it this way - any mistake made by anyone anywhere when he misspells .com as .cm will send him to the broken script. This could be anyone typing in one of a billion domains.
Additionally, a fair number of people who misspell the the domains of large sites such as Google will make multiple mistakes - they may mispell google.com as google.cm, but how many are prone to make multiple mistakes such as gogle.cm or googel.cm and be sent to the broken page?
What Are You Trying to Tell Us Here?
The point of what I am trying to say should have become clear by this point, but I will write it out nice and neat anyways: an neglect of details can lose you a lot of money. I do not know if this second landing page has ever actually worked for Agoga. Perhaps it has, and only stopped working 15 minutes before I stumbled upon it the first time. Perhaps it has never worked. The fact of the matter is, the person or persons who own Agoga.com (Whois data indicates Nameview, Inc, BTW) are losing thousands of dollars per day. It is probably safe to assume that they don’t even realize this; if they did, they would fix it in realtively short order.
The people responsible for this had an amazing idea, which they ran with 90% of the way to the perfect money-making opportunity. But they have missed a few small details which are costing them perhaps thousands of dollars per day. If they were to fix these small problems, they could probably nearly double their income.
I appreciate your comments and feedback!
Share This
 Comments(3)
Comments(3)